发布日期:2026-06-27 13:44 点击次数:73
【新智元导读】百度开源Unlimited OCR!3B参数500M激活现金足球外盘app平台,链接读完40页不失忆。作家疑似DeepSeek出走的OCR中枢大神。
就在刚刚,百度闷声干了票大的!
最新开源的Unlimited OCR,总参数3B,现实激活仅500M——放在大模子期间简直是个零头。
但便是这个小到离谱的模子,在OmniDocBench v1.5上拿下93.23%的空洞分,v1.6更是达到93.92%,径直刷新了端到端SOTA。
什么认识?v1.5同台竞技的选手里,235B的Qwen3-VL拿了89.15,72B的Qwen2.5-VL拿了87.02,不公布参数目的Gemini-2.5 Pro也唯一88.03。激活参数不到它们零头的选手,反手把它们全甩了。
更离谱的是,它还干了件之前莫得OCR模子干成过的事:链接解析40多页文档,不失忆、不放慢,一次推理从第一页读到终末一页。
目下,模子和代码都已同步上线GitHub和HuggingFace。
GitHub:
https://github.com/baidu/Unlimited-OCR
Hugging Face:
https://huggingface.co/baidu/Unlimited-OCR
为什么扫数模子都在「逐页失忆」
说到OCR,目下模子笨得让东说念主不测。
它们会把一件原来连贯的长程任务,硬生生切成几十个互不关系的小任务,再靠一个外部颐养器把扫尾拼凑缝起来。就像在跑一个for轮回,贬责完一页就把记挂清空,再从新开动下一页。
能用,但内容上只是工程的权宜之策,离确凿的智能还差着一大截。
究其原因在于,跟着输出越来越长,规范提防力机制下的KV缓存像滚雪球一样疯涨——内存吃不用,速率越来越慢。
这才是逼着扫数模子逐页贬责、通常「失忆」的确凿元凶。
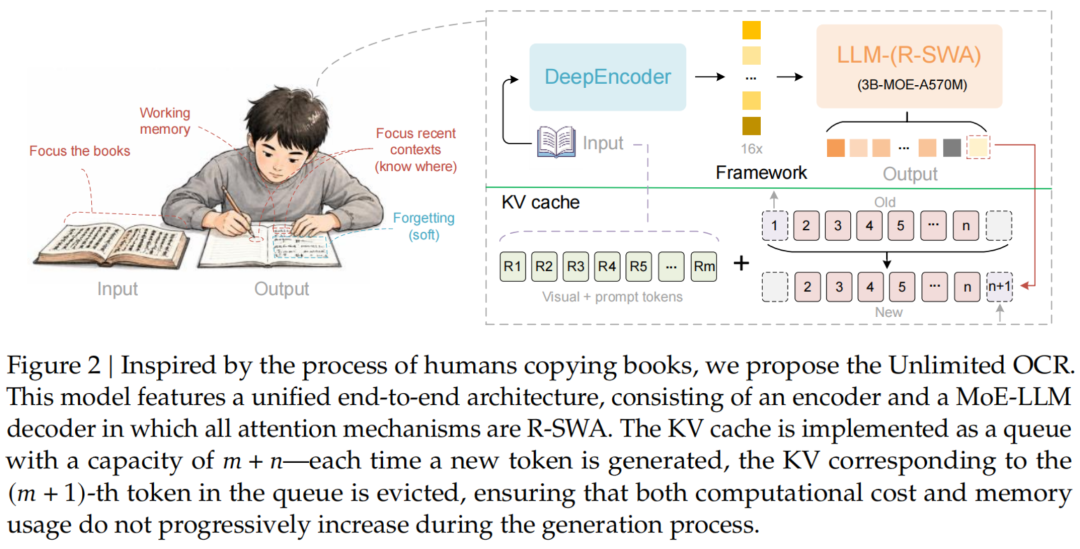
但东说念主类抄书,从来不是这样干的。
咱们会守护一种剖析的领会情景——眼睛盯着三个点:原书、刚写下的一小段、行将要写的下一个字。
早些写过的内容冉冉淡出脑海,最近的陡立文用来盯住现时进程。
这种才略有个很妙的名字:「软渐忘」(soft forgetting)。
恰是靠着这种「该忘就忘」的设施,东说念主材干在极低领会负荷下扛住超长任务。比如,抄一册书、译几百页、剖析转录数小时音频。
百度想作念的,便是把东说念主类这种「原文全局可见、记挂只保留最近几行」的提防力容貌,搬进模子里。让OCR告别失忆。
R-SWA:把「抄书的奥妙」写进提防力
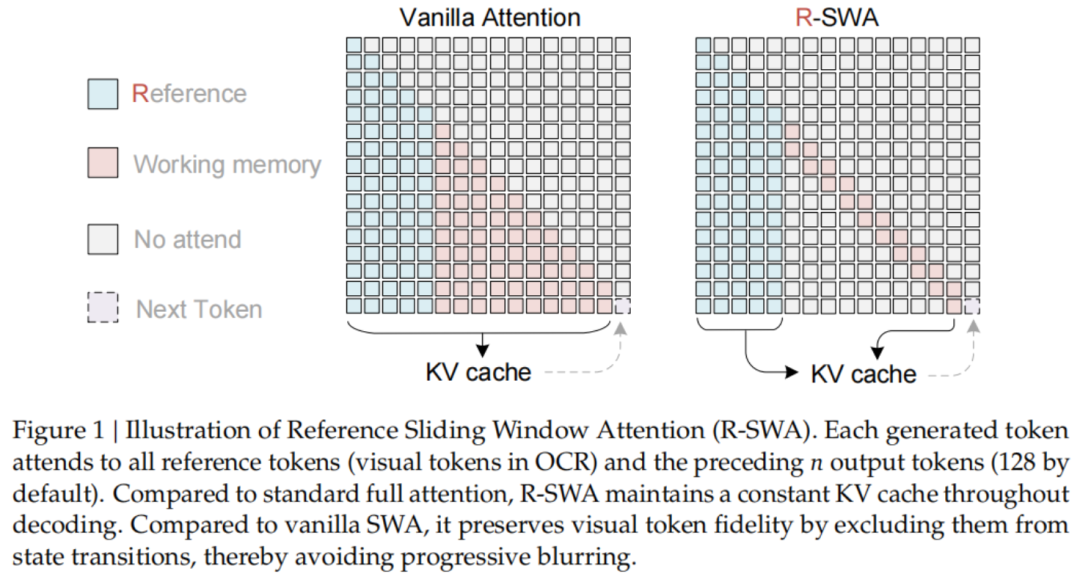
顺着这个想路,百度提议了陈诉里的中枢技艺——参考滑动窗口提防力(Reference Sliding Window Attention,R-SWA),精准对应前边说的东说念主抄书时的提防力形状。
具体来说,每生成一个token,R-SWA都会去看一王人「参考token」,也便是整张图像的视觉token和提醒词,保证模子遥远「看得见」好意思满原文。
但在输出这一侧,它只回看前边128个token,就像你抄书时只瞄一眼刚写的那几行。
落到终了上,Unlimited OCR把扫数提防力层全换成R-SWA,从而把KV缓存形成一个固定容量的部队。
每生成一个新token,最老的阿谁就被挤出去,大小遥远不变。输出1万个token和10万个token,内存占用是透顶一样的。
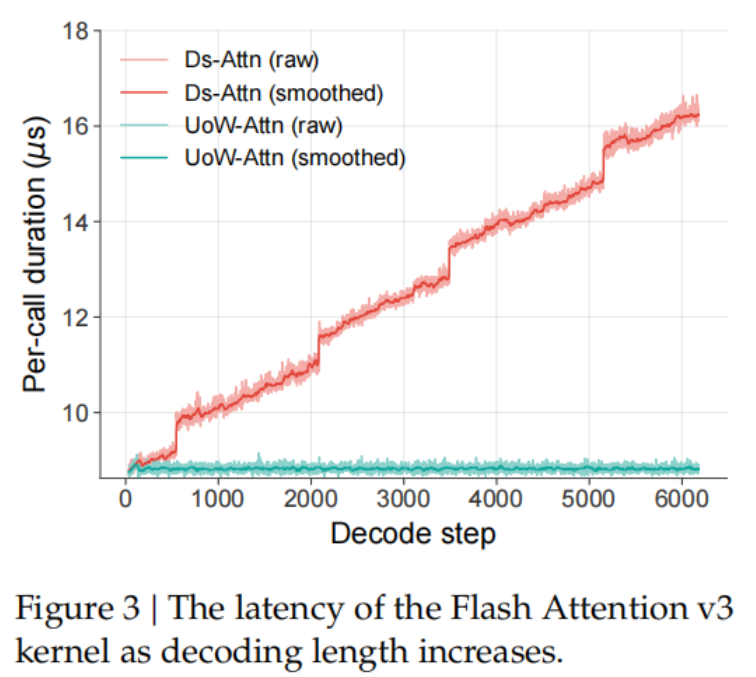
陈诉中Flash Attention v3的蔓延测试也一目了然。
DeepSeek OCR的规范MHA跟着解码步数加多,每步耗时稳步攀升;而Unlimited OCR的R-SWA从新到尾一条平线,因循守旧。
一次推理,读完几十页
这里还有一个至关进犯的合作:DeepEncoder。
这个最初在DeepSeek OCR中登场的编码器,能把一张1024×1024的PDF页面压缩到只是256个视觉token,压缩率高达16倍。
况且由于视觉token在R-SWA下不参与情景转动,因此无论文档多长,图像信息永远清清楚爽,不会随解码经由缓缓退化。
合作DeepEncoder的极致压缩和R-SWA的恒定缓存,Unlimited OCR在规范的32K陡立文里,一次前向推理就能转录数十页文档。
扫尾流露,同期输入20页文档,转录与原文逐字比对的剪辑距离仅0.057;即便输入40页以上,依然截止在0.11以下,掂量重叠输出的Distinct-35高达97%——几十页链接转录,简直莫得复读。
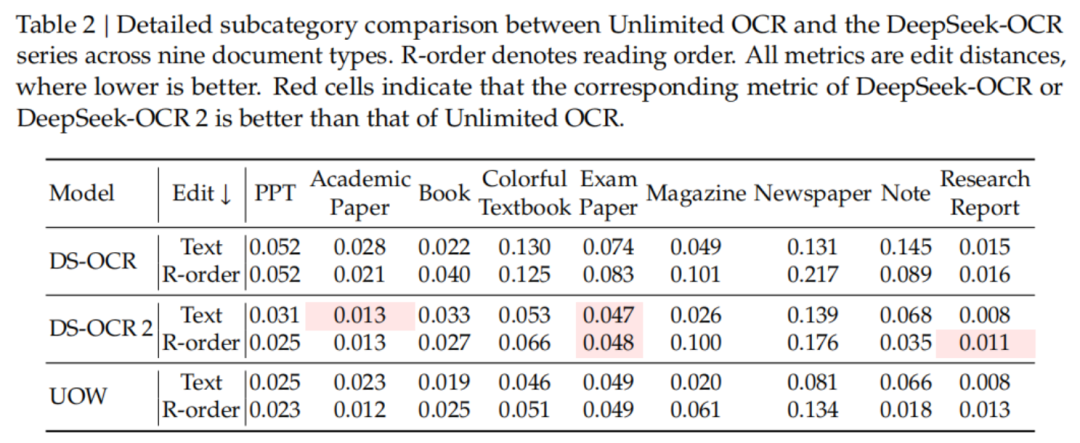
在OmniDocBench v1.5上,Unlimited OCR拿到93.23%的空洞得分,比DeepSeek OCR的87.01%越过6.22个百分点。
文本剪辑距离从0.073降到0.038,公式CDM从83.37飙到92.61,表格TEDS从84.97升至90.93。
在更新的v1.6上,雷同以93.92%拿下端到端SOTA。
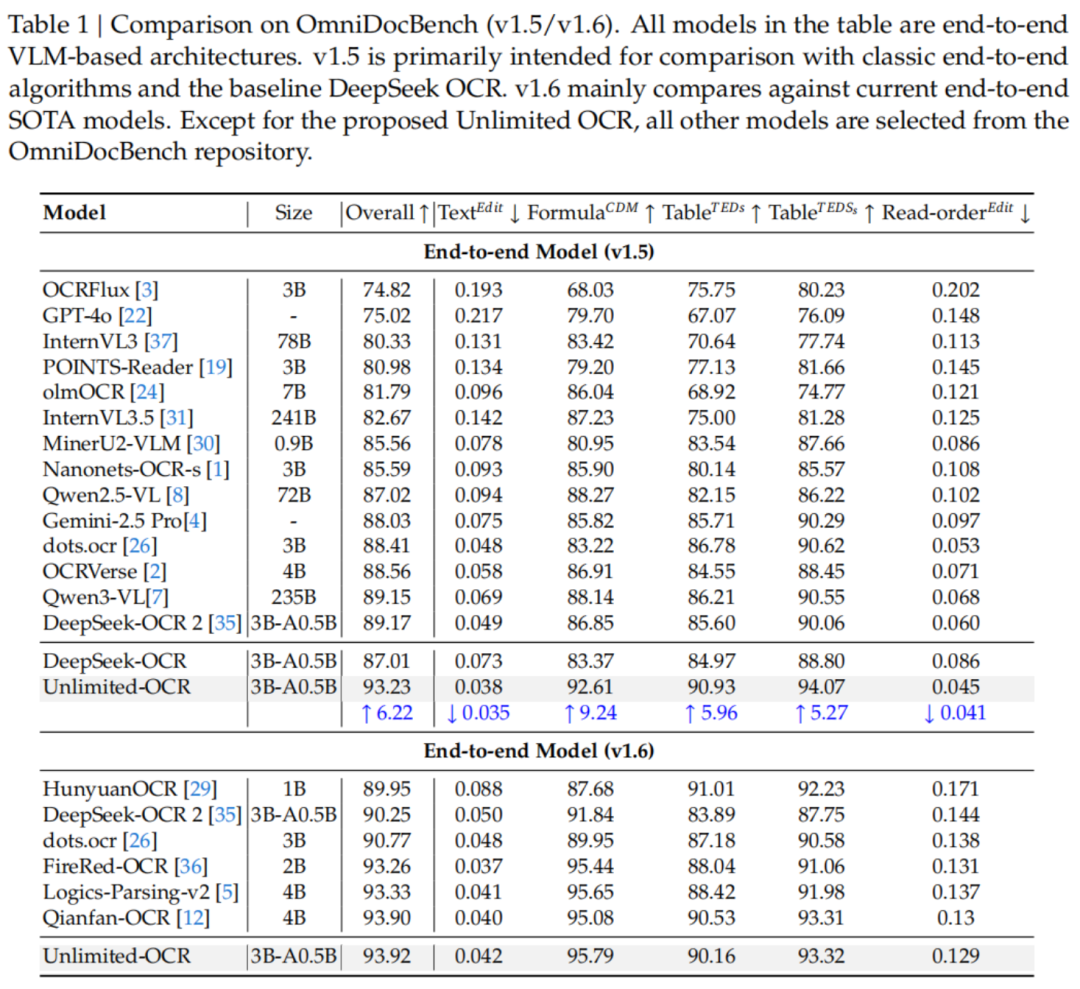
遵循方面雷同碾压。
输出达到6144个token时,Unlimited OCR的TPS是7847,DeepSeek OCR还是掉到5822,差距高达35%。
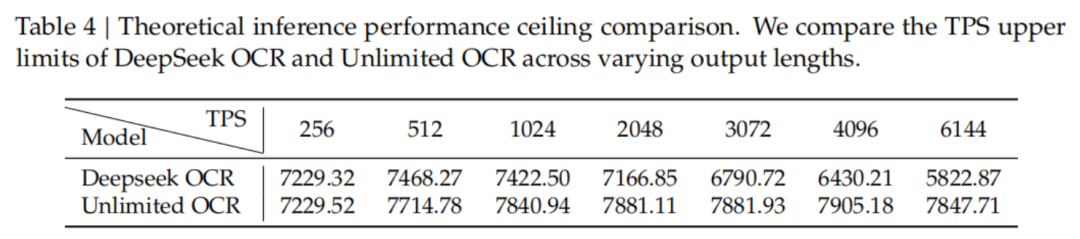
别忘了,这是一个500M激活的MoE小模子,在DeepSeek OCR基础上仅连接磨真金不怕火4000步的扫尾。
插足不算大,但恶果拔群——R-SWA对解析任务是一种确凿的「免费午餐」。
九大文档类型的细分对比中,PPT、论文、杂志、报纸无一短板,Unlimited OCR在文本和阅读王法两项上全面超越DeepSeek OCR,且在七个类别中最初DeepSeek OCR 2。
一位辽远的技艺总监
跑分说收场。但这份陈诉确凿有道理的场地,是行文容貌。
从副标题的口吻到技艺的叙事,读过DeepSeek那几份技艺陈诉的东说念主,几页下来就会认为似曾剖析。
末尾还断言R-SWA是通用解析机制,而OCR只是第一站。
一篇OCR陈诉,硬是写出了探索通用智能的滋味。
然后,是阿谁最让东说念主堤防的场地——作家名单。
中枢孝敬者三位:Youyang Yin,Huanhuan Liu*(神志leader),YY†(技艺总监)。
两个东说念主用本名,唯一技艺总监挂了个两字母缩写。有点道理。
天然论文没多说,但GitHub致谢栏却把痕迹递了过来:Deepseek-OCR和Deepseek-OCR-2,排在致谢前两位。

顺着这条线往回找。DeepSeek OCR从一代到二代,中枢作家遥远三个东说念主:魏浩然、孙耀峰、李宇琨。肃清支小部队,从无到有。
本年4月DeepSeek发V4,魏浩然名字背面多了星号——已辞职。
三个东说念主里,唯一他还是公开离开。
再看阅历。魏浩然,阶跃星辰配置,主导拓荒了端到端OCR最早跑通的开源标杆GOT-OCR2.0。到DeepSeek后,更是一手搭起整条OCR线,DeepEncoder、MoE解码器,一代到二代都是他的团队。
才略、时辰线、签字容貌,三条都对得上。
国内OCR圈不大,能作念出R-SWA这种级别打破、还对DeepSeek OCR架构有「亲手作念过」级别熟习的东说念主,一只手数得过来。魏浩然是其中最显眼的那一个。
如斯一来,YY或者率便是魏浩然了。
百度,依然能打
昔时几年,PaddleOCR简直是国产OCR的代名词。开源、轻量,产业落地最广——从手机端到就业器到镶嵌式拓荒,隐敝了最主流的运用场景。
不外之前百度更侧重产业运用。踏实性、部署资本、场景隐敝是坚韧,「用前沿商榷理念重塑OCR范式」这个标的并非其叙事要点。
而魏浩然作念的,恰恰便是这件事。
从GOT-OCR2.0的端到端一次解析,到DeepSeek-OCR的视觉压缩,再到R-SWA——先想了了OCR应该长什么样,再作念出来。
一边是产业落地最训练、场景隐敝最广的工程底座;一边是端到端长程解析最前沿的商榷试吃。两者叠加,补王人的不单是一个技艺短板,而是一种「既能大限制铺开、又能不息引颈范式」的好意思满才略。
百度本年把AIDU东说念主才诡计升级为集团级神志、薪酬不设上限。对一个想把商榷作念到落地的东说念主来说,百度多年铺下来的产业底座,比单纯的高薪更有劝服力。
魏浩然要是简直选了百度,逻辑就很了了——这里有最训练的产业底座,也有把商榷推到前沿的空间和资源。
要是他简直把R-SWA奉行到ASR和翻译,那百度手里合手着的就不单是一个OCR模子,而是一套通用长程解析的技艺框架。
论文揣测里还留了一句:下一步,陡立文窗口训到128K,构建prefill pool让模子学会自动翻页。
要是作念到了,OCR就不再是识别一页笔墨现金足球外盘app平台,而是合资一整本书。
Powered by 足球外盘网站有哪些推荐(中国)官网入口 @2013-2022 RSS地图 HTML地图
Copyright Powered by站群 © 2013-2024